
みなさん,こんにちは。
シンノユウキ(shinno1993)です。
今回は画像認識入門ということで,Pythonのニュートラルネットワークライブラリ:Kerasと手書き数字のデータ・セット:MNISTを用いて,画像認識に入門してみます.非エンジニアが機械学習の深い部分を理解せずとも,道具として機械学習を利用できるように書いてみます.ではいきましょう!
まずは準備
開発環境は「Google Colab」を利用よう
まずは準備です.でもその前に開発環境を用意しましょう.開発環境としては,Google Colabを想定しています.予め機械学習に必要なライブラリもインストールされていますし,機械学習に必要なGPUも利用できるからです.まだ用意されていないという方は,以下の記事を用意してみてください.

データをインポートしよう
次にデータをインポートしましょう.今回は「MNIST 」というデータ・セットを使用します.
MNISTには手書きの数字画像が,学習用にトレーニング用に60000個,そのテスト用に10000個用意されています.このデータ・セットを活用して,機械学習に入門を果たしてみましょう.
まずはデータのインポートからです.以下のコードを実行してください.
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
データ・セット:MNISTは,kerasに予めインストールされていますので,それを経由してインポートします.そしてそれを,mnist.load_data()でロードし,トレーニング用データとテスト用データにそれぞれ代入しています.
データを表示してみよう!
では,インポートしたデータを確認してみましょう.
import sys
print('以下の数字は' + str(y_train[0]) + 'です')
for item in x_train[0]:
for i in item:
sys.stdout.write(str(i).zfill(3))
sys.stdout.write('\n')
これで以下が表示されるはずです.

ゼロ以外の部分を見ると,なんとなく数字の5に見えますか?
では少しコードの解説をします.
このコードは非常に単純なもので,x_trainの要素の2次元配列の中身をわかりやすいように表示しているだけのものです.
最初の行でsysライブラリをインポートしています.これは今回の数字を表示させるためだけに利用するライブラリですので,それほど深く理解する必要はありません.
2行目では,y_trainに含まれる正解用のラベルを表示しています.printするためには数値型だと出力できないので,文字列型に変換しています.
それ以降の行では,配列:x_trainにアクセスしています.x_trainのそれぞれの要素には,28×28のピクセル値が2次元配列として格納されています.なお,ピクセル値は0が白で255に近づくほどに黒くなります.
そのピクセル値をsys.stdout.write(str(i).zfill(3))で出力しています.sys.stdout.writeは,改行しないprintのようなものだと理解してください.str.zfill(3)はゼロパディングするための関数で,0→000のようにゼロ埋めしています.
そして,2次元配列の1行が出力し終わるたびに,sys.stdout.write('\n')で改行コードを出力しています.
つまり,MINISTではこんな感じで,
- x_train:28×28のピクセル値
- y_train:正解用のラベル
が格納されています.この訓練用の画像と正解用のラベルを学習させることで,モデルを作成していくのです.
データを整理しよう!
次にデータを整理しましょう.適切にデータ整理することで,機械学習の精度を向上させるこいとができます.まずは,以下のコードを入力してください.
import keras
import keras.utils
from keras import utils as np_utils
#一次元配列に変換
x_train_reshape = x_train.reshape(60000, 784)
x_test_reshape = x_test.reshape(10000, 784)
#正規化
x_train_reshape_std = x_train_reshape.astype('float32') / 255
x_test_reshape_std = x_test_reshape.astype('float32') / 255
#one-hotベクトルに変換
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
1-3行目では,必要なライブラリのインポートを行っています.
6-11行目は正規化と呼ばれる部分です.現在のピクセル値は0-255の範囲を持っていますが,これを最小値0,最大値1の範囲に変換します.これを正規化と呼び,データを扱いやすくできるのです.
6, 7行目では,まず,トレーニング用データとテスト用データの両方を1次元配列に変換しています.先でも説明しましたが,これらのデータは28×28の2次元配列でしたね.ですが,それを1次元配列に変換しても,データの特徴として見る分には全く影響ありません.2次元配列で「5」とラベリングされたデータは,1次元配列でも「5」ですので.
そして10, 11行目でその1次元配列を正規化しています.ピクセル値は0-255の範囲にありますので,255で割ることで0-1の範囲に収まります.こうすることでデータが扱いやすくなるのですね.
また,14, 15行目で正解用のラベルデータを変換しています.これは,後々に教師あり学習を行うためです.教師あり学習のためには,ラベルデータはone-hotベクトルである必要があります.one-hotベクトルとは,たとえば今回のように数字データが0から9まである場合,ラベルが2を示すなら,以下のように該当する場所にだけ1入力されているような配列のことです.
0,1,2,3,4,5,6,7,8,9 [0,0,1,0,0,0,0,0,0,0]
教師あり学習の場合は,このようにする必要があるのですね.np_utils.to_categorical(y_train, 10)とすることで,10通りのデータ数に応じたone-hotベクトルができます.
モデルを構築しよう!
では,機械学習に必要なモデルを構築していきましょう.今回はSequentialモデルを構築します.Sequentialモデルはレイヤーを積み上げていくだけの単純なモデルです.ここではニューラルネットワークなどに関する詳細な説明は割愛し,良質な入門書に譲りたいと思います.
では,以下のコードを入力してください.
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(units=512, input_dim=784))
model.add(Activation('relu'))
model.add(Dense(units=10))
model.add(Activation('softmax'))
model.compile('rmsprop', 'categorical_crossentropy', metrics=['accuracy'])
1, 2行目では必要なライブラリとモジュールをインポートしています.
3行目ではSequentialモデルのインスタンスを作成しています.これ以降,このモデルにレイヤを追加していきます.
4,5行目では,出力層が784個のノード,それが行き着く中間層が512個のノードのレイヤを加え,活性化関数としてReLu関数を指定しています.活性化関数は中間層に入力された信号の総和を変換するような働きをします.ReLu関数は入力した値が0以下の場合は0,それより多い場合はその値をそのまま出力する関数です.
6, 7行目では,さらに中間層が10個のレイヤを加えています.活性化関数はsoftmax関数を使用しています.softmax関数はニューラルネットワークの最後によく用いられる活性化関数で,確率的な表現を可能にしてくれます.
8行目はモデルをコンパイルしています.これはよく用いられるものをそのまま使用しています.
モデルを訓練しよう!
では次にモデルを訓練しましょう.以下のコードを入力してください.
#教師あり学習の実行 model.fit(x_train_reshape_std ,y_train ,epochs=2)
このコードは,x_train_reshape_stdをy_trainの正解用ラベルデータで訓練しています.epochsでは訓練の回数を指定しています.もう少し多い方が良いかもですが,時間がかかる場合がありますので,今回は2回としています.ではこのコードを実行してみましょう.以下のようになれば成功です.
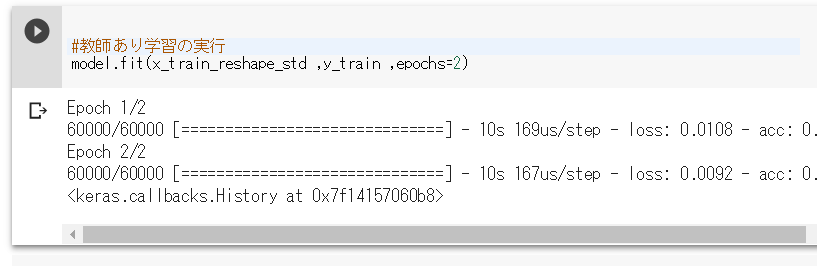
テストしてみよう!
ではいよいよテストしてみます.テスト用のデータが,今回訓練したモデルでどれだけ正確に判定できているかを見てみます.以下のコードを入力してください.
#テスト
test_loss, test_acc = model.evaluate(x_test_reshape_std, y_test)
print('test_acc:', test_acc)
2行目でテストを実行し,3行目でその結果を出力しています.
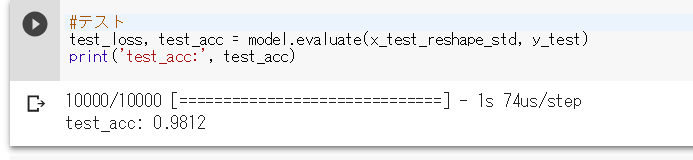
このようになればOKです.今回はtest_accが0.9812,およそ98%の正答率という結果が得られました.かなり高い正答率といえるのではないでしょうか.
まとめ
今回はKerasとデータ・セット:MNISTを用いて手書き文字認識を行ってみました.かなり入門要素の強い内容で,まだまだ実用的ではありませんが,これを皮切りに画像認識を頑張って勉強してみたいと思います!